인덱스 스캔 방식을 알아보기전 where절 가공방식에 대해 설명해 드리겠습니다.
WHERE절의 좌변이 아닌 우변을 가공할 것
- 숫자형 컬럼 인덱스 가공
SELECT ename, sal*12 FROM emp WHERE sal * 12 = 36000;
-> SELECT ename, sal*12 FROM emp WHERE sal = 36000/12;
- 문자형 컬럼 인덱스 가공
SELECT ename, job FROM emp WHERE substr(job,1,5)='SALES';
-> SELECT ename, job FROM emp WHERE job LIKE 'SALES%';
- 날짜형 컬럼 인덱스 가공
SELECT ename, hiredate FROM emp WHERE DATE_FORMAT(hiredate, '%Y') = '1981';
-> SELECT ename, hiredate FROM emp WHERE hiredate BETWEEN STR_TO_DATE('1981/01/01', '%Y/%m/%d')
and STR_TO_DATE('1981/12/31', '%Y/%m/%d') + INTERVAL 1 DAY;
현재 사용하고 있는 DB는 MySQL로 MySQL은 InnoDB 엔진을 사용하며, InnoDB 엔진은 B+Tree를 인덱스 트리 구조로 사용하고 있습니다 따라서 B+Tree를 기준으로 작성하도록 하겠습니다
Index Range Scan
[자료구조] B- Tree , B+ Tree
B- Tree B-Tree는 탐색 성능을 높이기 위해 높이를 균형있게 유지하는 Balanced Tree의 일종입니다. B-Tree는 이진 트리와는 다르게 하나의 노드에 여러개의 데이터를 가질수 있으며, 두개 이상의 자식노
sebang.tistory.com
인덱스를 통해 B+Tree를 수직으로 탐색 후 leaf 노드에서 필요한 범위까지 수평적으로 탐색하는 방식입니다.
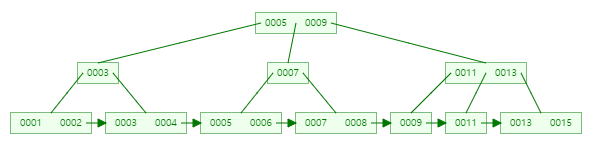
select * from park_mgt_info where park_info_id<3;

<, <=, >, >=, between, IS NULL, IS NOT NULL 등 범위를 조건으로 설정시 Index range scan을 진행함을 알 수 있습니다.
Full Index Scan, Full Table Scan
Index Range Scan과 달리 수직적인 탐색이 없이 리프 블록 처음부터 끝까지 수평적인 탐색만 존재하는 Scan 방식입니다.
Full Scan을 하게되면 첫번째 leaf 노드를 수직 탐색후 나머지 leaf노드에 대해 순차적으로 전체를 탐색하게 됩니다.
select count(*) from park_mgt_info;
Index Full Scan은 인덱스가 크고, 데이터가 적은 경우에 적합한 방법입니다. 그래서 Index Full Scan은 대용량 데이터를 처리할때는 비효율 적일 수 있어 대용량 처리에는 Full Table Scan을 사용할 수 있습니다. Full Table Scan은 테이블 전체를 스캔하여 데이터를 검색하는 방법으로 인덱스가 존재하지 않거나, 인덱스를 사용하지 않는 쿼리를 수행할때 사용됩니다.
테이블의 row 갯수가 적고, 인덱스 키 값의 분포도가 낮은 경우 Full Table Scan이 더 빠를 수 있습니다. 또한, 인덱스를 사용하지 않는 쿼리에서는 Full Table Scan을 사용해야 합니다.
반대로, 인덱스의 분포도가 높은 경우 Index Full Scan이 더 빠를 수 있습니다. 이는 인덱스의 특성상 중복되지 않은 값이 인덱스 키 값으로 사용되는 경우에 해당합니다. 이 경우 인덱스를 사용하면 정확한 값을 빠르게 찾을 수 있습니다.
요약하면, Full Table Scan은 테이블 전체를 스캔하여 데이터를 검색하는 방법이며, Index Full Scan은 인덱스를 전체적으로 스캔하여 데이터를 검색하는 방법입니다. 두 가지 방법은 데이터 검색에 사용되는 상황에 따라 적절한 방법을 선택하여 사용해야 합니다
'Database' 카테고리의 다른 글
| SQL 기본(GROUP BY, HAVING, ORDER BY, JOIN) (0) | 2023.09.02 |
|---|---|
| SQL 기본 (SELECT, WHERE) (0) | 2023.08.19 |
| 데이터 모델과 SQL (0) | 2023.08.19 |
| SQL_데이터 모델링의 이해 (0) | 2023.08.12 |
| [Database] 인덱스의 개념, 장단점 (0) | 2023.03.28 |



